Multi-view panorama tokens
Each panorama is treated as a view and encoded by a DINOv2-based backbone with local and cross-view attention.
ECCV 2026
AutoLab, School of Artificial Intelligence, Shanghai Jiao Tong University
*Equal contribution. †Corresponding author.

Abstract
The rise of home-deployed embodied AI systems creates a growing need for fast, metric 3D reconstruction of residential spaces. Pinhole-camera pipelines struggle with large indoor residences because narrow fields of view require dense capture and long alignment chains. CasaMaestro addresses this by taking only twenty to fifty sparse multi-view indoor panoramas and directly predicting metric depth with camera poses, enabling immediate point-cloud reconstruction of an entire house with full coverage.
CasaMaestro combines a multi-view DINO backbone, a panoramic camera pose decoder, and ERP data augmentation. Experiments show robust high-quality results on both real-world and synthetic scenes, making sparse panoramic capture a practical foundation for house-scale indoor assets and closed-loop simulation.

Motivation
Pinhole models either lose context under sparse capture or accumulate drift across dense sequences. CasaMaestro uses sparse panoramic viewpoints to keep the full house visible while avoiding long incremental alignment chains.

Method
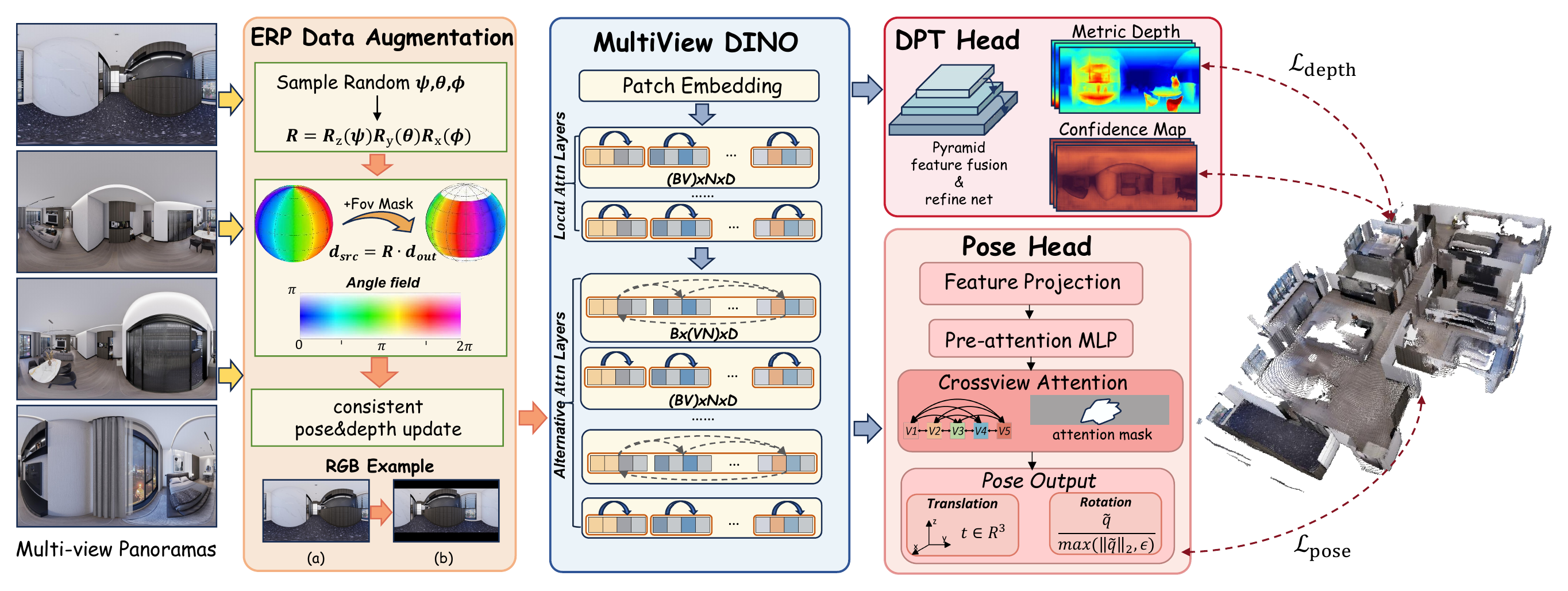
Each panorama is treated as a view and encoded by a DINOv2-based backbone with local and cross-view attention.
A lightweight cross-view pose head aligns condensed view features to predict translation and quaternion rotation.
DPT-style depth prediction and camera extrinsics are fused into metrically consistent house-scale point clouds.
Equirectangular remapping generates additional pose-view pairs while preserving scene geometry.
Interactive Meshes
Downsampled reconstruction points are converted into compact surfel meshes for smoother browser playback. Drag to orbit, scroll to zoom, and switch between houses below.
Results


0.903
AUC@30, with 2.608 rotation mean and 2.132 translation mean.
0.927
AUC@30, outperforming prior methods under sparse panoramic capture.
0.078
Overall AbsRel with 0.205 RMSE and 0.972 delta1.
21.98%
Average AbsRel decrease compared with the best previous results.
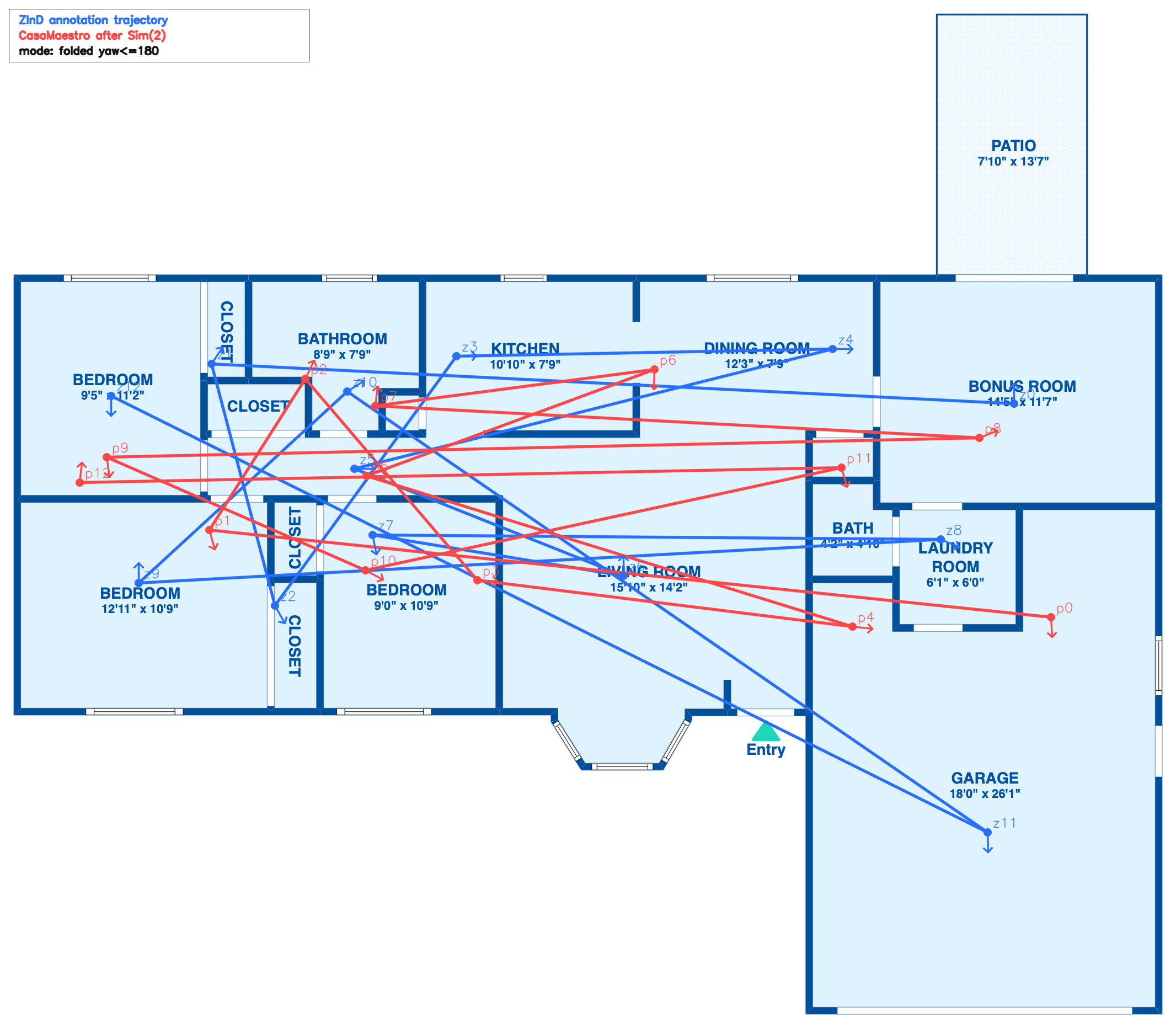
Supplement Figure 1
The supplementary comparison shows that uniform mean aggregation can hide large errors on one axis, while axis-wise max loss keeps optimization focused on the weakest pose component.

Supplement Figure 2
The complete lack of connecting viewpoints between adjacent rooms can lead to poor predictions. This suggests the remaining failures may require substantially more data scale or stronger spatial layout awareness to resolve.
Citation
@inproceedings{ji2026casamaestro,
title = {CasaMaestro: Multi-View Panoramas for House-Scale 3D Reconstruction},
author = {Ji, Yuzhou and Yang, Xiaotian and Zhang, Zhipeng},
booktitle = {European Conference on Computer Vision},
year = {2026}
}